
Datenanalyse mit Python – Auswertung von Daten mit Pandas, NumPy und IPython von Wes McKinney, 2.Auflage aus dem O’Reilly Verlag
Die Verarbeitung von Rohdaten insbesondere in Unternehmen wird immer wichtiger, da das Datenvolumen ins exorbitante anwächst. Mit der Datensammelleidenschaft ist es aber nicht mehr getan, die Daten auszuwerten und zu analysieren, um daraus Rückschlüsse zu bilden und sich strategisch besser aufzustellen ist die Hürde, die viele Unternehmen nehmen müssen. Insbesondere der Mitarbeiter, der an vielen stellen mit großen Datenmengen in Berührung kommt, ist gefordert. Datenanalyse mit Python von Wes McKinney führt durch das Dickicht und erklärt Schritt für Schritt, wie man seine Daten mit Python und seinen Bibliotheken: Pandas, Numpy, matplotlib und Seaborn bearbeitet.
Datenanalyse mit Python – Auswertung von Daten mit Pandas, Numpynd IPython
Das Lehrbuch von Wes McKinney, mit dem Titel: „Datenanalyse mit Python – Auswertung von Daten mit Pandsas, Numpy und IPython“ ist bereits in der 2. Auflage im O´Reilly Verlag erhältlich. Das Lehrbuch umfasst 14 Kapitel.
Eine Inhaltsangabe ist über den Download-Buttons erhältlich.
Schritt für Schritt in die Materie eintauchen
Das Lehrbuch fängt mit der Installation der nötigen Entwicklungsumgebung [engl.integrated development environment: IDE] an. Wes McKinney hat hierfür Anaconda mit dem Jupyter Notebook gewählt, was eine sehr gute Wahl ist, da das Jupyter Notebook dem Nutzer den programmierten Code direkt in der nächsten Zeile anzeigt. Insbesondere bei der Zusammenführung von verschieden Datensätzen, die beispielsweise aus xlsx, csv und ods vorliegen. Außerdem eignet sich das Jupyter Notebook besonders für alle späteren Cloudanwendungen, sodass das erworbene Wissen, aus dem Lehrbuch in folge Projekten, gut ausbauen lässt. Der Schwerpunkt des Lehrbuches „Datenanalyse mit Python“ besteht in der Programmbibliothek: Pandas.
Nach einigen Erklärungen zu den Grundvoraussetzungen steigt das Lehrbuch „Datenanalyse mit Python“ ab Kapitel 3 in die volle Materie ein. In jedem Kapitel wird dem Nutzer kurz und prägnant das Themenfeld, wie etwa Nutzung von Tupels, Listen und Dictionarys erklärt, darauf folgen Programmcodes, die das erworbene Wissen vertiefen und schließlich zu deren vielseitiger Verwendbarkeit.
Jedes Kapitel enthält die verwendeten Typen, Modi, Funktionen, Operatoren, alternative Syntax, Argumenten etc. und die zugehörigen Beschreibungen kurz und bündig in Form einer Tabelle aufgeschlüsselt, sodass eine Verwirrung des Nutzers ausgeschlossen wird und er rasch in die Lage versetzt wird täglich wiederkehrende Problemstellungen in seiner Datenanalyse zu lösen.
Über den Download-Button finden Sie eine Leseprobe zu Kapitel 4, aus Datenanalyse mit Python
Bonuskapitel 12 bis 14
Die letzten beiden Kapitel sind für den geübten Nutzer gedacht, der sein Wissen vertiefen möchte, wie etwa Tipps für eine produktive Codeentwicklung mit IPython und Einführung in Modelierungsbibliotheken in Python.
Zur Übersetzung
Die Übersetzung des Lehrbuches „Datenanalyse mit Python – Auswertung von Daten mit Pandsas, Numpy und IPython“ von dem Autor Wes McKinney, ist durch das Dreiergespann Christian Tismer, Kristian Rother und Katrin Lichtenberg gemacht worden und ließt sich wie aus einem Guss.
Fazit zu „Datenanalyse mit Python – Auswertung von Daten mit Pandsas, Numpy und IPython“
Alles in allem, befähigt das Lehrbuch den Nutzer sich in kürzester Zeit zum Datenanalysten zu entwickeln und die Welt der Zahlen zu Ordnen und zu visualisieren. Die Zielgruppe Datenanalysten in Forschung, Wirtschaft, Marketing oder Marktforschung.

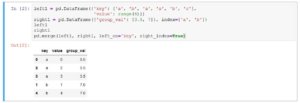

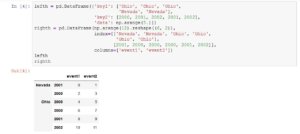
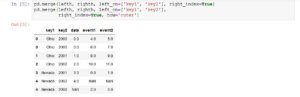
Das Programm beinhaltet noch weitere Funktionen, die ausführlich erklärt werden. Da wir Ihnen aber die Freude am Entdecken und Ausprobieren nicht nehmen möchten, sollten Sie selbst zu dem Buch greifen.

Bücher zur Datenanalyse mit Python gibt es so einige, aber am besten lernt es sich von Herrn Wes McKinney dem wohlwollenden Schöpfer und Diktator von Pandas. Bereits in jungen Jahren hat er sich mit unzähligen Tools zum Analysieren von Daten herumquälen müssen, was ihn dazu bewog, Python zu lernen und Pandas zu schaffen. Wes McKinney schuf Pandas, um seinen Benutzern das Maximum an Effizienz auf den Weg zu geben und die Produktivität im Kleinem wie im Großen zu steigern.
Pandas ist eine Open Source Programmbibliothek der Programmiersprache Python, die unzählige raffinierte Hilfsmittel seinen Nutzern zur Verfügung stellt. Heute kennt Pandas so ziemlich jeder, der mit großen Datenmengen in irgendeiner Form in Berührung kommt. Schließlich ist Pandas eine der meistverbreiteten Programmbibliotheken weltweit.
Einige Eckdaten zum Autor von Wes McKinney zu Datenanalyse mit Python in der 2. Auflage
– Namhafte Open-Source-Projekte wie Ibis und Pandas
– Softwareentwickler und Unternehmer
– Mathematikstudium am MIT mit einem Bachelor of Science Abschluss
– 2007 bis 2010 AQR Capital Management
– 2010 – 2012 Python-Entwickler und Berater
– 2012 Mitbegründer von Lambda Foundry Inc.
– 2013 CEO von Datapad
– 2018 PMC-Mitglied der Apache Software Fundation
Noch mehr Informationen über den Autor finden Sie auf seiner Website

Wes McKinney
Kathrin Lichtenberg (Übersetzung)
Datenanalyse mit Python
Auswertung von Daten mit Pandas, NumPy und IPython
2. Auflage
Oktober 2018, 542 Seiten, Broschur
O’Reilly
ISBN Print: 978-3-96009-080-9
ISBN PDF: 978-3-96010-213-7
ISBN ePub: 978-3-96010-214-4
ISBN Mobi: 978-3-96010-215-1
44,90 € Buch, Lieferung in 2-4 Tagen
35,99 € E-Book (PDF + ePub + Mobi)
Was man mit Datenanalysen anstellen kann
Datenanalysen sind so ziemlich das Spannendste, was es auf der Welt gibt. Sie fragen sich, warum dem so ist? Nun stellen Sie sich vor Sie hätten den Zugriff auf Rohdaten – beispielsweise einige csv-Dateien von Google. Nehmen wir weiter an, in diesen csv-Dateien wären Trackingdaten von Nutzern mit deren Standorten, den Datumswerte ihrer Suchanfrage mit Schlagwörtern zum jeweiligen Themenfeld enthalten. Nehmen wir weiter an, dieser Personenkreis hätte die Grippe.
Grippe geplagte suchen im Normalfall im Internetbrowser nach Begriffen, wie etwa: Husten, Schnupfen, Medizin gegen Erkältungen usw. Solche Daten kann man zu einer Tabelle bündeln und in eine Form bringen, sodass man genaue Diagramme erstellen kann und beispielsweise über eine Landkarte werfen kann, um dann genaue Vorhersagen treffen zu können, wann eine Grippewelle vor der eigenen Haustür eintrifft. Solche Analysen sind auch so ziemlich mit allen anderen Rohdaten machbar. Die einzige Herausforderung, die besteht, ist sich eine Frage zu stellen und die Parameter für die Beantwortung dieser Frage zusammenzustellen. Im Nu ist man dann in der Lage die Zukunft vorherzusagen. Faszinierend nicht wahr!